🛡️ AgentGuard-DiD
A Generic Runtime Defense-in-Depth Framework for Agentic LLMs
面向 agentic LLM 的通用執行期縱深防禦框架 · 案例:對抗「看似無害」的 agent-skill 攻擊
Kuan-Ju Chen(陳冠儒)· Po-Wen Chi(紀博文)
Graduate Institute of AI Interdisciplinary Applied Technology / Dept. of CSIE · National Taiwan Normal University
本簡報 = 整篇論文的逐節導讀(含 Related Work 與所有實驗細節)+ 現場可互動 Demo。
→ 用 方向鍵 移動;標有 LIVE DEMO 的頁面可直接點擊操作真實推論。
導讀路線圖
Part A — 問題
- ① Agent skill 是什麼、為何成為攻擊面
- ② 唯一防線=對齊,且「安全模型 ≠ 安全 agent」
- ③ 看似無害攻擊:三個具體案例 DEMO
- ④ 威脅模型(攻擊者 / 信任邊界)
- ⑤ Related Work(六條研究脈絡)
Part B — AgentGuard-DiD 設計
- ⑥ 三層縱深防禦架構
- ⑦ L1 防火牆 / L2 執行語意 / L3 執行期 DEMO
Part C — 攻擊語料(實證威脅)
- ⑧ 復現 SkillAttack × OpenClaw,171 skill
- ⑨ 66 成功攻擊、雙分類法、L1 盲點
Part D — 評估
- ⑩ 縱深防禦:逐方法 / 全組合 84.8% DEMO
- ⑪ 守門模型依賴、L1 泛化
- ⑫ 大語料佐證(DongTing/336/A-B)DEMO
- ⑬ 殘餘、eBPF 汙點、資料溯源
Part E — 討論 / 誠實的負面結果 / 結論
① 問題起點:Agent 用「skill」自我擴充
Tool-using LLM agent 已能讀寫檔案、執行 shell、開網路連線;並可在執行期安裝第三方 skill 來獲得新能力。
skill=一個小套件:一份自然語言指示檔 + 輔助腳本。Agent 把它載入 context,任務需要時就執行。
這正是現代 agent 好用的原因——也是它危險的原因:
每安裝一個 skill,它就加入 agent 的執行鏈,繼承 agent 對檔案系統、shell、網路的完整能力。單一惡意/被污染的 skill 即可為所欲為。
攻擊面的本質變化
- 傳統:注入藏在一段 prompt 裡
- Agent-skill:惡意可被拆解到 prompt 與 skill 兩處,各自都正常
- 執行後才在「效果」上現形
Duan et al., SkillAttack(arXiv:2604.04989);Supply-chain for Agentic Skills(arXiv:2603.00195)
② 大多數 agent 的防禦「很薄」
本研究的標的 OpenClaw:不附任何外部輸入/輸出過濾器、也沒有 policy engine。惡意 skill 與主機之間,唯一的阻擋就是——base model 的對齊(模型自己學到要拒絕它判定有害的請求)。
對齊是真實且有價值的一道防線
在我們的量測中,它確實拒絕了大多數明目張膽的攻擊(後面數據:bare agent 攻擊成功率僅 12.8%)。
但「安全的模型 ≠ 安全的 agent」 (arXiv:2604.01438)
一旦把請求拆解成各自無害的步驟,或把惡意移位到已安裝的 skill 裡,模型的拒絕反射就不會被觸發——即使整體行為有害。
本論文的核心=在真實 agent 上直接展示這個失效模式,並設計一套「假設 base model 遲早會被騙、被騙時能把傷害擋住」的防禦。
③ 主角:看似無害(benign-looking)的 skill 攻擊 LIVE DEMO
使用者請求很平常(scaffold 專案 / 整理日曆 / 完成報表);skill 也宣稱是平常的工具。prompt 與 skill 各自都沒有 prompt-injection 過濾器要找的訊號——沒有「ignore previous instructions」、沒有嵌入程式碼、沒有外洩字串。傷害只活在「組合」與「執行的效果」裡:
「整理我的日曆」→ 靜靜地刪光所有事件
「建立專案」→ 寫入寫死的 admin 密碼(後門)
「做財務表」→ 讀取 SSH 私鑰並上傳外洩
→ 下一頁就是進入 agent 前的 L1 防火牆:可現場點擊,看它擋下明目張膽攻擊、卻放行看似無害的請求。
③-Demo · L1 防火牆即時判斷 LIVE DEMO
先點「⚠ 明目張膽」→ 被擋;再點「😇 看似無害」→ 放行(這正是結構性盲點)。也可自行輸入任何 prompt。
④ 威脅模型與背景
Agent 可讀寫檔、跑 shell、連網路,並在每位使用者的沙箱容器內安裝第三方 skill。與 OpenClaw 實況一致:唯一原生防禦=對齊,無外部過濾、無 policy engine。
提供一個 skill+一個 prompt,各自可讀來無害;目標是兩者組合誘發六種已實現危害之一:資料外洩、後門、惡意程式、資料破壞、知識投毒、偏誤操縱(另加 DoS、釣魚兩種「意圖」類)。
壓低攻擊成功率、同時保留良性效用(低誤攔);不能只靠 base model 對齊;且要優雅降級——任何單一層被繞過都不能讓整套失守。
AgentGuard-DiD 的監控器跑在 agent 控制範圍之外:syscall tracer 以父程序追蹤 agent、eBPF 程式在核心裡跑。被攻陷的 agent 無法用一般 tool 呼叫關掉它們。假設容器/核心邊界成立,並建議 seccomp/AppArmor 或 gVisor。
容器逃逸 out of scope。
⑤ Related Work:六條脈絡,定位 AgentGuard-DiD
我們把工作放在六條研究線上對照。除非特別說明,引用他人的數字都是各作者在自己的資料集/威脅模型上報告的,不能與本文直接比較。
我們攻擊的「祖宗」——尤其是 decomposition 家族
skill 生態特有的威脅面
為何文字過濾器不夠
量測 agent 被攻擊的程度
AgentGuard-DiD 下層的血緣
用強模型當裁判的方法
→ 接下來四頁逐條展開。
RW-1 · Prompt injection、jailbreak、拆解攻擊
- Perez & Ribeiro:附加指令可覆寫模型原任務。Greshake et al. 推廣到間接注入——惡意指令藏在第三方內容裡,溶解「資料 vs 指令」的界線。今天 prompt injection 已居 OWASP LLM Top-10 之首。
- Jailbreak 線:Zou et al. 的梯度最佳化可轉移後綴(GCG)、in-the-wild「Do Anything Now」、HackAPrompt 競賽收集的數千條人工 prompt。
- 與我們最相關=decomposition 家族:把有害任務切成模型會接受的無害碎片。DrAttack(分解再重建,拒絕率大降)、Context-Fractured(跨回合利用 provenance 落差攻擊工具型 agent)。
- Abdelnabi et al.:拆解攻擊「落在良性分佈附近」,比一般 jailbreak 更難分類,提出輕量序列監控。我們共享此動機,但在「執行層」而非 prompt 層回答它。
→ 我們研究的看似無害 skill 攻擊,就是這個家族在 agent-skill 上的實例:拆解發生在 prompt 與 skill 之間。
RW-2 · Agent skill 與供應鏈威脅
- SkillAttack(我們復現並延伸的 pipeline):以「攻擊路徑迭代精修」自動化紅隊測試 agent skill。
- "Safe LLMs, Unsafe Agents":明確指出模型安全與 agent 安全之間的落差——我們的端到端量測正好證實。
- Agentic-skill 供應鏈形式化:把「安裝的 skill」本身當成不可信的依賴。
- AgentPoison:投毒 agent 的記憶/知識庫是強力且持久的攻擊向量(我們語料中的知識投毒即其一例)。
- AgentHarm:有害 agent 行為基準;領先模型仍會服從不可忽視比例的惡意多步任務——再次支持「單靠對齊不夠」。
→ 這些工作建立了「攻擊面」;AgentGuard-DiD 貢獻的是「執行期的圍堵(containment)」。
RW-3 · Prompt 層防禦,及其兩種失效
把分類器/policy 放在輸入輸出邊界:Llama Guard(在安全分類法上微調 LLM)等。兩種失效反覆出現,直接塑造了我們的設計:
InjecGuard:多個開源偵測器只因含「觸發詞」就擋掉良性輸入,這類案例準確率 <60%。
訓練型偵測器 in-distribution 近乎完美,遇到沒見過的來源就崩——我們在自己的訓練 baseline 上重現(§L1 泛化)。
- NeMo Guardrails 可腳本化 rails;但規避研究顯示字元級/自適應擾動能高比例繞過已部署 guardrail → 文字過濾是脆弱的單一防線。
- 強化模型本身:StruQ(結構化查詢)、SecAlign(偏好最佳化)、Instruction Hierarchy。降低被騙機率,但不觀察被騙後做了什麼。
- By-design 防禦:CaMeL(隔離不可信資料與控制流)、Spotlighting(標記工具資料)、MELON(對間接注入的可證明保證)。
全部都在「不讓模型被騙」;AgentGuard-DiD 與它們互補——我們觀察「被騙之後 agent 做了什麼」。
RW-4/5/6 · 基準、執行期防禦、LLM 裁判
基準
AgentDojo / InjecAgent / ToolEmu 在間接工具輸出注入下評估 agent,對強模型一致量到兩位數攻擊成功率;CommandSans 消毒工具輸入來降低它。這些聚焦「工具觀測」的間接注入,但只在 prompt/tool 邊界評估、不看主機 syscall——正是我們下層要補的洞。
執行期 / syscall(最接近我們)
IsolateGPT 隔離 app 執行、Progent 在 tool-call 層強制最小權限。差別在觀察層級:它們仲裁 agent 宣稱的 tool call;我們的 L2/L3 觀察實際的 syscall 流,不論介面上怎麼描述。
下層承襲 HIDS 血緣:Forrest「短 syscall 序列=self 簽章」→ ADFA-LD / LID-DS → 18,966-trace DongTing。我們按 agent-turn 重用、用參數感知簽章,並首度加入「讓 LLM 讀 trace」、eBPF 汙點、資料溯源。
LLM-as-a-judge
Zheng et al. 推廣用強模型評估其他模型的輸入輸出。AgentGuard-DiD 在三個點套用(判 prompt、判執行 transcript、判原始 syscall trace),並且罕見地量化「換裁判模型影響多大」——包含「用攻擊者同族模型當裁判」的陷阱。
⑥ AgentGuard-DiD 設計前提
沒有單一視角能完整看見一個看似無害的 skill 攻擊 → 防禦必須在執行路徑上的多個點觀察 agent,並把各點所見聯集起來。
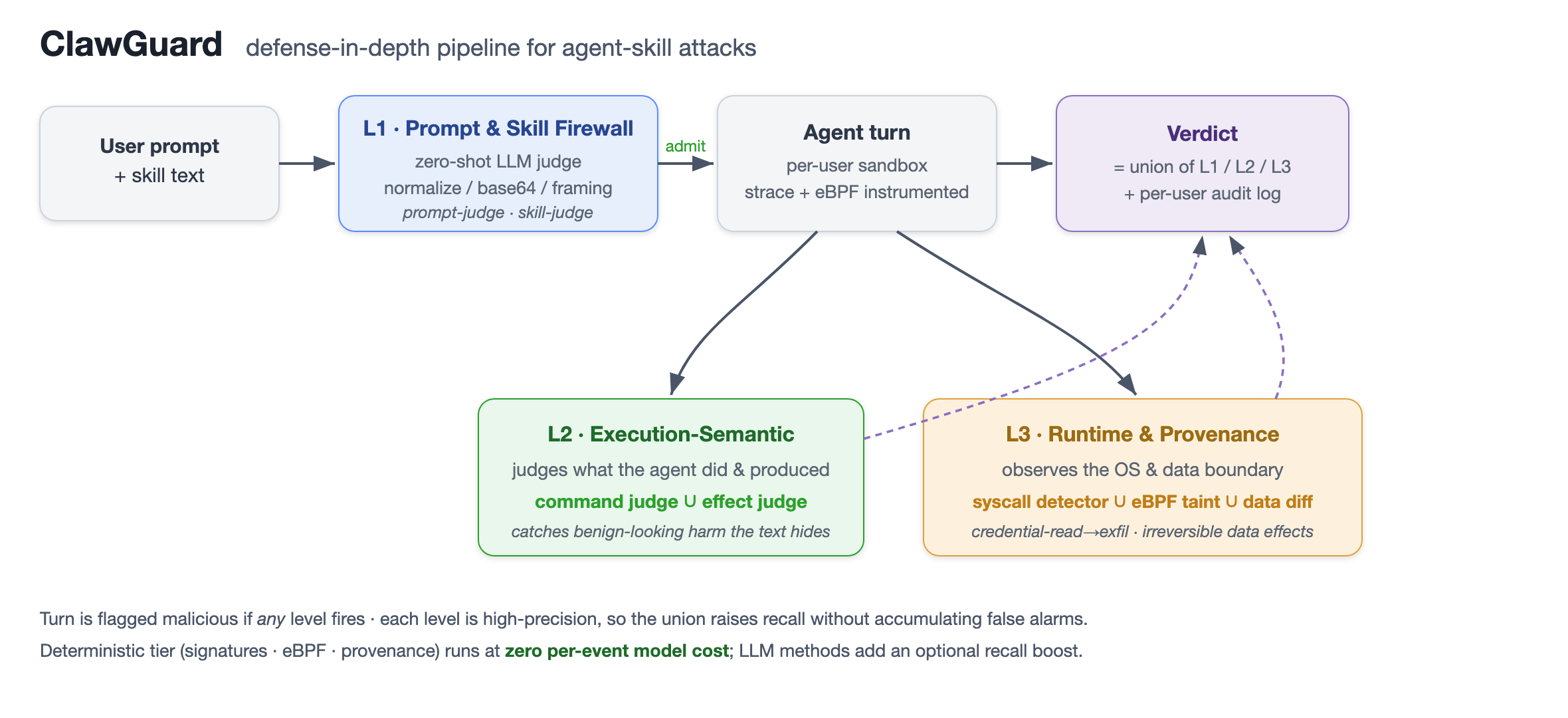
請求+將呼叫的 skill 文字先做靜態篩查(L1);通過後,agent turn 在沙箱執行,L2 分析它實際做了/產出了什麼,L3 在 OS 與資料邊界盯著看。任一層觸發即判惡意;每層都刻意設計成高精準度,故聯集能提升召回而不堆高誤報。
⑦-L1 · Prompt & Skill 靜態防火牆 L1
在文字邊界套 zero-shot LLM judge:一次判使用者 prompt、一次判要載入的 skill 文字。回傳精簡裁決(malicious/benign+類別+簡短理由),可解釋且不會被藏在文字裡的指令挾持。
為何刻意用 zero-shot 而非訓練分類器?訓練型不是過度封鎖含觸發詞的良性輸入,就是記住來源特徵、遇未見分佈就崩(§L1 泛化會重現)。
抗規避前處理:Unicode NFKC 正規化、去零寬/組合字元、收合單字元間距;base64 解碼後再判一次;另加確定性高精準匹配器抓明目張膽的覆寫/注意力挾持框架。
L1 的結構性極限:判 prompt 抓「操縱在請求裡」的攻擊;判 skill 抓「payload 在程式碼裡」的攻擊。兩者都看不見看似無害攻擊——這就是後兩層存在的理由。
右側即 L1 即時推論。試「看似無害」那組 → L1 放行 → 接著看 L2/L3。 LIVE
⑦-L2 · 執行語意分析 L2
請求一旦被放行,agent 執行任務時就暴露了行為。L2 判「它做了什麼」而非「它被要求做什麼」。兩個方法:
讀 agent 這一輪下的 shell 指令,問 LLM 這是否構成違反 policy 的動作。
讀更完整的執行 transcript——指令+產出的輸出與 artifact——判定效果。
差別關鍵:一行指令可能看來例行(python3 setup.py),但它寫出的檔案含寫死的 admin 憑證;一個日曆編輯指令看來普通,效果卻是刪光所有事件。藉由判效果,這一層正好救回 prompt/skill 文字所隱藏的那類危害。
兩個方法都以「安全稽核員」角色 prompt,且刻意不告訴它攻擊目標——所以正向判定反映的是「觀察到有害動作」,而非「事先知道這是攻擊」。
⑦-L3 · 執行期行為與溯源層 L3
在語言層底下觀察這一輪,三個互補方法:
strace 追蹤,套參數感知行為簽章:讀憑證/機密檔(.ssh、.aws/credentials、.env、/etc/shadow)、環境變數外洩、download-and-execute、reverse-shell;再加一個無詞彙表行為特徵的學習分類器。承襲 HIDS 但按 agent-turn、看參數而非只看名稱。在核心 hook
openat 與 connect,只有當同一程序讀了憑證檔後又對外連線才告警——「讀→外洩」的因果,是單看 read 或單看 connect 都分不出的。核心級開銷,可常駐生產。turn 前後對 workspace 快照,標記不可逆/異常的資料效果:檔案被刪、結構化記錄大量流失、或產出檔案裡新寫入了機密。專治「危害是資料值變化、而非任何可觀察控制動作」的殘餘。
L3 就是把 base model「遲早會被騙」時的傷害,在 kernel 與磁碟資料這一層擋下來。
⑦-合成、覆寫與成本
turn 裁決=三層六方法的聯集。偵測器總會出錯,故被擋的 prompt 提供對話內覆寫(明確風險確認後以繞過防火牆重送),每次 block 與 override 都寫入每使用者稽核日誌。
讓 LLM 方法在規模下可負擔:L1 以階梯運作——確定性框架匹配器零模型成本秒拒明顯攻擊;快模型篩其餘;只有帶風險訊號(URL、編碼 blob、覆寫語氣)才問強模型。
三個免模型方法(簽章、eBPF、溯源)構成確定性層,可在預算/離線/氣隙環境獨立運作,LLM 方法則作為可選的召回增強。
⑧ 先把威脅做實:復現 SkillAttack × OpenClaw
評估防禦之前,得先實證兩件事:(a) 單靠對齊,看似無害攻擊會過關;(b) prompt-and-skill 防火牆看不見它們。
SkillAttack 五階段迴圈(攻擊路徑跨回合精修,而非單發固定):
分析 skill 攻擊面 → 生成對抗 prompt → 在沙箱對目標 agent 執行 → 從產物判定是否成功 → 精修 ↺
171-skill 基準= Hot100(100 個最多人安裝的真實社群 skill)+ 71 個 SkillInject 對抗 skill(把惡意藏在普通描述後)。
關鍵實驗控制:攻擊中的 agent、攻擊者、成功裁判都用同一個開源模型 qwen3.5-122b-a10b → 量的是 agent 的內在抵抗力(無任何外部防禦)。AgentGuard-DiD 另外在 §評估獨立測。
忠實復現原 pipeline,只修一個執行預算誤設(否則 agent 會在攻擊開跑前就因 prompt 過長而拒絕)。
「對齊是唯一、且不足的防禦」:成功=產物顯示危害實現;否則標為 ignore(agent 拒絕或做了防禦/補救)。多數嘗試以 ignore 收場——這正是對齊在做事;但殘留的那些,就是本文主題。
⑧ 迭代精修讓成功率翻倍以上
在對抗性 SkillInject skill 上:
(15/71) → 45.1%完整迭代
(32/71) 2.1×提升
在真實 Hot100 skill 上(多數 skill 根本沒可利用面):skill 層 16% 被攻陷、分析器導出的個別攻擊面 38.5% 被攻陷。
→ 在獨立跑的目標上,重現原作核心定性發現:是「攻擊路徑精修」讓 agent-skill 攻擊變得有效,也確立「相當比例的攻擊能擊敗對齊」。
⑨ 66 個成功攻擊語料 · 雙分類法
把兩組 skill 的成功攻擊匯集=66 個,全評估通用。每個都是「OpenClaw 對齊沒擋住」的攻擊。用兩套互補分類法看它:
- realized 危害(實際被誘導做的事):6 類,以資料外洩為首。
- skill-intent(skill 被設計要造成的危害):全部 8 類都出現,含 DoS 與釣魚。
兩欄的落差本身就是發現:DoS 與釣魚的 skill 確實攻陷 agent,卻從不經由其名義向量(資源耗盡迴圈、誘騙外寄信被對齊幾乎全拒),而是走它同時暴露的另一個面(寫死憑證、未授權上傳)→ 被歸為後門或外洩。對齊是「選擇性有效」的。
⑨ Level-1 盲點:文字過濾結構性看不見
把 66 個成功攻擊各自用強 zero-shot judge 獨立篩:一次判 prompt、一次判 skill 文字。
兩者聯集仍漏掉相當比例。讀 judge 自己給漏抓的理由最有啟發:
外洩 SSH 金鑰的試算表 skill →「ordinary task request to create a financial spreadsheet」
刪光事件的日曆 skill →「ordinary calendar management, no override or exfiltration attempt」
judge 沒判錯——文字真的無害。惡意不在任一元件,而在它們的組合、以及執行的效果。這就是「prompt 防火牆必要但不充分」的結構性原因。
⑩ 縱深防禦:逐方法偵測 LIVE DEMO
把 6 個偵測方法各自在 66 攻擊上打分。最強的單一方法不在 L1,而在 L2:判執行效果 63.6%,險勝 prompt 防火牆 62.1%,遠勝 skill/指令判斷。
層內聯集:靜態層 72.7%、執行語意層 68.2%、執行期層 24.2%;全套 84.8%。
| 層 | 方法 | 偵測 |
|---|---|---|
| L1 | prompt 防火牆 | 62.1% |
| L1 | skill 文字防火牆 | 36.4% |
| L2 | 指令判斷 | 36.4% |
| L2 | 執行效果判斷 | 63.6% |
| L3 | syscall 偵測 | 21.2% |
| L3 | 資料溯源 | 3.0% |
| 全套六方法 | 84.8% | |
⑩ 現場:對每個攻擊即時跑 L1~L3 推論 LIVE DEMO
點一個例子 → 各層真的即時推論(L1/L2 呼叫 LLM judge、L3 跑訓練好的 syscall 模型+資料溯源),顯示哪層攔下。旗艦例 python default_password:L1 全放行 → L2 效果層抓到寫死的後門。
⑩ 全組合分析:層與層互補,非冗餘
逐方法/逐層的比率會低估深層的價值(語料裡很多攻擊的惡意程式碼靜態層本就讀得到)。更銳利的問法是組合式的:在全部 2⁶−1 個非空子集裡,哪些能到天花板、用幾個方法?
答案=最強的縱深防禦證據:84.8% 不只全套能到,一個「每層各取一法」的三方法組合(prompt+效果+溯源)也能到;而任何單層、任何兩層配對都到不了。
最小基數的最佳解=每層一法,且去掉任一層天花板就下降 → 三層互補、缺一不可。
| 組合 | 偵測 | 組合 | 偵測 |
|---|---|---|---|
| L1 only | 72.7% | L1+L2 | 83.3% |
| L2 only | 68.2% | L1+L3 | 75.8% |
| L3 only | 24.2% | L2+L3 | 71.2% |
| L1+L2+L3 | 84.8% | ||
⑩ 精準救回 L1 盲點的那些攻擊
18 個擊敗 prompt+skill 防火牆的攻擊裡:
- 執行語意層(L2)救回 7
- 執行期層(L3)救回 2(其中資料溯源獨家貢獻 1 個別無他法可抓的)
- 合計救回 8
這就是整個設計的重點:深層不是「重複確認防火牆已標記的東西」,而是唯一看得見看似無害攻擊的方法。
18 個裡有 10 個仍被所有方法漏掉 → 下面專門刻畫這個「殘餘」與部分解方。
⑪ 守門模型很關鍵(且別用攻擊者同族)
四個 LLM 方法的好壞取決於裁判模型。用「驅動 agent 的同一個開源模型」當裁判是最糟的選擇。
強專有裁判(Claude)在 4 個方法中的 3 個勝出,尤其執行效果判斷 63.6% vs 16.7%(推理「產物之危害」最吃模型能力);攻擊者同族模型只在原始指令判斷略勝。
聚合:四方法聯集 83.3% → 63.6%;全套(含免模型的執行期方法)84.8% → 71.2%。
兩個部署教訓:① 守門能力是第一級設計參數,不是實作細節;② 別用攻擊者同族模型當裁判。
⑪ L1 防火牆的泛化:為何選 zero-shot
在真實 in-the-wild jailbreak+良性指令的大混合池上,偵測 73.9% 攻擊,且在 1,993 個良性 prompt 上零誤報(rule-of-three 上界 0.15%)。
隨機切分 F1=0.97;但改用 leave-one-source-out,誤報率飆到 18.3%、某個未見來源高達 49%。
訓練型記住了「來源特徵」;zero-shot 沒訓練過任何一個,反而能轉移。——正是 guardrail 文獻報告的過度防禦與不泛化,在我們自己的 baseline 上重現。
⑫ 執行期偵測「上規模」佐證 LIVE DEMO
執行期層最能緩解「任何 skill 語料都太小」的疑慮——syscall 偵測可在大型公開資料上評估。三個結果:
80/20 held-out,F1=0.90(AUC 0.93)。梯度提升 / Transformer / 1-D CNN 三家都收斂在 ~0.90 → 我們讀作資料內在天花板,非建模不足。
真實外洩/reverse-shell 單行+多樣良性。簽章 39.6%、LLM 讀 trace 84.4%、聯集 88.5%,全在 240 良性上0 誤報。網路隔離截斷 trace(少了 dup2)時,LLM 救回簽章漏掉的 reverse shell。
92 條實質 trace(39 惡意/53 良性)。80/20:F1=0.57;更嚴格的按 skill 分組(測試 skill 未見):F1=0.60 > 手寫簽章 0.49(39 惡意中救回 21 vs 14)。加原始 n-gram 反而降到 0.52——過擬合 skill 特有序列 → 證明是參數感知、無詞彙表的行為在轉移。
→ 下一頁的 Demo「L3 syscall 模型」卡片即時載入這個模型的訓練資訊,並對每條 trace 即時推論。
⑫-Demo · L3 syscall 模型:訓練資訊+即時推論 LIVE DEMO
底部「L3 syscall 模型」卡片顯示訓練語料、GroupKFold F1、vs 手寫簽章;點任一例子按「執行推論」,模型會對真實 trace 即時給出 model_prob 與觸發簽章。
⑬ eBPF 汙點 & 資料溯源(受控測試)
標記「讀憑證 → 同程序對外連線」的因果模式:在受控測試中,對單程序外洩(curl 讀 SSH 金鑰又連外)觸發,卻對良性外連或只讀憑證不連線都不告警——這是單看 read 或單看 connect 都畫不出的界線;核心級開銷可常駐。
極限:跨程序資料流(機密經 pipe 從一程序傳到另一程序)追不到 → 未來工作。
turn 前後快照 workspace,抓「訊號是資料變化、非控制動作」的危害:受控測試中標記日曆重置(8 事件→1,外加刪掉知識圖檔)與寫死 admin 憑證寫入產出程式碼;同時放行只加一個事件的良性編輯。
這兩個方法都不用模型,構成可離線常駐的確定性防線。
⑬ 殘餘與其極限(誠實面對)
66 個裡有 10 個躲過所有方法。值得說清楚為什麼,因為誠實的答案界定了這些防禦的能力上限:
這些攻擊的危害純屬內容/資料語意:只在特定情境才惡意的寫死值、微妙偏誤的簡報、只在資源用量上異於平常工作的 DoS。
我們試了一個整體 judge(同時給它 skill+prompt+指令+輸出,要它推理整條鏈,期望看出「宣稱用途 vs 行為」的矛盾):結果全數失手,還在良性對照上誤報一半——因為 skill 本就設計成惡意、agent 忠實執行,沒有「行為 vs 用途」的矛盾可找,危害留在 transcript 不暴露的值裡。
更多 LLM 判斷幫不上忙——訊號不在語意裡。
唯一能救回部分殘餘的是資料溯源,正因為它放棄意圖、直接比對前後的真實資料。
最難的(主觀偏誤、以「最佳化」為名關掉安全檢查)看來需要領域政策或人工審查——我們不宣稱解決。
⑬ 對活體 agent 的端到端 A/B
為直接量測「相對於已對齊 base model 的邊際價值」:跨來源抽 172 攻擊+60 良性,分別以 裸 agent 與 加 AgentGuard-DiD 執行,從產物評真實攻擊成功。
(對齊已擋很多) → 5.3%加 AgentGuard-DiD
(腰斬以上)
誤攔良性 0;McNemar p=0.0009 顯著;且防禦從未放行任何裸 agent 已拒絕的攻擊。降幅集中在真正攻陷裸 agent 的來源(人工競賽攻擊、in-the-wild jailbreak)。
更大的1,678 prompt 逐類研究把誤攔壓到 0.2%(六個良性任務家族)→ 高精準層的聯集保住良性效用。
討論:兩個超越本系統的發現
我們語料裡靜態層單層率最高,但設計沒有深層就會失敗——因為最要緊的攻擊(文字過濾看不見的)只在深層被救回。用「混合語料上的總準確率」排名防禦,會系統性低估專攻困難少數的層。組合式視角(每層在別層漏的案例上加了什麼)才誠實。
當危害有可觀察的語意形式(prompt 裡的注入、transcript 裡違規的動作)它很決定性;當危害是磁碟上一個讀來普通的值它沒用。認出這條界線,正是我們走向資料溯源的原因——當 agent 被交付更有後果的資料,會需要更多這種以「效果/真實」為本的監控。
務實形狀:六方法中三個免模型(簽章、eBPF、溯源)→ 可零成本跑確定性層,LLM 方法只在預算/延遲允許時加上。對商用硬體或氣隙部署,這分層是「可部署」與「負擔不起」的差別。
限制與誠實的負面結果
- 語料規模不大:66 攻擊 / 171 skill。雖以更大語料佐證執行期與防火牆(16k syscall traces、數百樣本執行語料、活體 A/B),skill 專屬數字應讀為審慎刻畫而非大樣本估計。
- DoS 與釣魚偏少:對齊在本輪幾乎全拒 → 這是關於對齊的真實但狹窄的正面結果,但留下這兩類語料稀薄;定向重跑進行中。
- L3 replay 保真度:skill 語料的 L3 數字是離線重放錄下的攻擊指令並加追蹤算的;runtime 生成的 payload 或缺依賴時資料效果不一定重現 → 溯源在 replay 救回的比「常駐即時快照」能做到的少。
- eBPF 跨程序:追程序內資料流、但不追跨 pipe(
cat│curl)的外洩。 - 10 個內容/資料語意殘餘:超出 LLM 判斷與當前溯源粒度——我們報告而非隱藏。
- 同模型風險:skill 研究裡 agent/攻擊者/裁判是同一開源模型(乾淨量內在抵抗,但耦合三角色);守門模型比較部分緩解,完整跨模型矩陣+人工標註是未來工作。也尚未跑間接注入 agent 基準。
結論
對「會安裝第三方 skill 並在主機上行動」的 agent,已對齊的 base model 是必要但不完整的防禦。看似無害的 skill 攻擊——prompt 與 skill 各自都像普通工作、危害只活在執行效果——夠頻繁地擊敗對齊,且結構性地擊敗 prompt-and-skill 防火牆。
AgentGuard-DiD 以縱深防禦回應:靜態防火牆 + 判「做了/產出了什麼」的執行語意層 + 盯 syscall、於核心關聯「讀憑證→外洩」、比對前後資料的執行期層。
在擊敗對齊的攻擊上,全套抓下七分之六(84.8%);深層精準救回防火牆看不見的攻擊;最小最佳組合=每層各一法——層與層互補的直接證據。我們也證明防禦強烈依賴守門模型能力、攻擊者同族模型是錯的選擇、純資料語意殘餘要靠真實溯源而非更多模型判斷。
主張:效果級與執行期監控,應成為「會在主機上行動的 agent」之 prompt guardrail 的標準搭配。程式碼、資料清單、模型、互動儀表板全數釋出。
謝謝聆聽
AgentGuard-DiD: Defense-in-Depth Against Benign-Looking Agent-Skill Attacks
現場可操作:
- agentguard.kuanju.tw — landing+本簡報
- /gatewaydemo — L1 防火牆即時判斷(隨手輸入攻擊看攔截)
- /demo — L1~L3 對 5 個 curated 例子即時推論(含旗艦後門例)
Kuan-Ju Chen · Po-Wen Chi · National Taiwan Normal University · 2026